
As part of an exploratory dialogue someone from our old world (longevity) asked if we might use some data intelligence to tease out a relationship. The relationship in question was individual wealth versus size of life insurance policy. The relationship mattered because an investor holding longevity risk will see her returns suffer (substantially) as the […]
Category Archives: webscraping
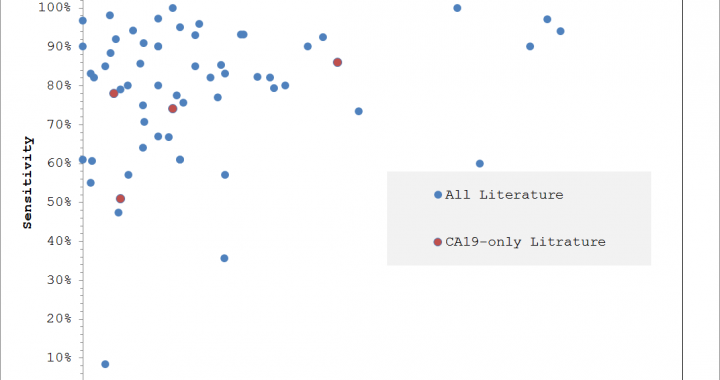
Harvesting medical data: a small project
Going through some old files I came across this piece of work we performed for a client some time ago – Search Project “…specific/sensitive biomarkers in certain cancers from the scientific literature and other online sources. For example might we be able to search in pancreatic or lung cancer for reports of biomarkers with say […]

PDF is evil!
Hopefully you’re already convinced that you can grab whatever data you wish from webpages (and if not, later examples will hopefully tip the balance in our favour) but sooner or later you are going to ask about pdf. And let’s face it, when the latest report comes out that everyone wants to be able to […]

Combined Harvester
Let’s change gears, skip the code, and look at a harvester in action. Here’s the url for you to play with and a user-guide / description – Data Harvesting: Stock Prices From the S&P500 we choose up to 5 tickers for their daily adjusted-closes. Store those into memory with “Load Prices” against a time-frame of our […]

101 Data Harvesting
Building out a fully-fledged data-harvesting bot is not our purpose here, instead we will quickly demonstrate a 101 harvester in action against a financial variable. Even though simplified, the exercise is useful: the modules of work shown below are consistent for any level of complexity. Let’s work with FX since it is straightforward. (We’ll likely look at […]

A stupefying evening, one dead mouse and a python…
Late one evening reading Nathan Yau’s excellent “Visualize This” some years ago, I stumbled upon this undecipherable – url = ‘http://www.wunderground.com/history/airport/KBUF/2009/1/1/DailyHistory.html’ page = urllib2.urlopen(url) soup = BeautifulSoup(page) dayTemp = soup.findAll(’span’)[4].text print dayTempurl = ‘http://www.wunderground.com/history/airport/KBUF/2009/1/1/DailyHistory.html’ page = urllib2.urlopen(url) soup = BeautifulSoup(page) dayTemp = soup.findAll(‘span’)[4].text print dayTemp Apparently there were Pythons involved, the soup was a parser, […]